Sample annotation overview
data("multi_trt_day_samples")Samples are grouped by Treatment and Collection time with the following group sizes:
| Time | Treatment | n |
|---|---|---|
| 4 | CTRL | 3 |
| 4 | SOC_TRT1 | 4 |
| 4 | SOC_TRT1_TRT2 | 3 |
| 4 | SOC_TRT1_TRT3 | 4 |
| 4 | SOC_TRT1_TRT3_TRT2 | 4 |
| 8 | SOC_TRT1 | 3 |
| 8 | SOC_TRT1_TRT2 | 3 |
| 8 | SOC_TRT1_TRT3 | 4 |
| 8 | SOC_TRT1_TRT3_TRT2 | 4 |
Total number of samples is: 32
Task
Samples are to be blocked in batches for scRNA-seq.
- 8 samples can be processed per day (batch)
- Within day they need to be split into 2 parallel runs (4 + 4).
This data set is also used in the nested dimensions example. Here, we focus on using different methods for the optimization.
Setting up batch container
We allocate surplus positions in the batch container and some excluded positions to check that all optimization methods support empty container positions.
# Setting up the batch container
bc <- BatchContainer$new(
dimensions = c(
batch = ceiling(nrow(multi_trt_day_samples) / 8),
run = 2, position = 5
),
exclude = tibble::tibble(batch = 4, run = c(1, 2), position = c(5, 5))
) |>
# Add samples to container
assign_in_order(samples = multi_trt_day_samples)
bc
#> Batch container with 38 locations and 32 samples (assigned).
#> Dimensions: batch, run, positionFirst optimization with fixed shuffling protocol
The samples are distributed to 4 batches (processing days). We use
the osat scoring on sample Treatment and Time,
using first a shuffling protocol with a fixed number of sample swaps on
each iteration.
Note that doing 32 swaps on 38 free container positions does not make sense, since each swapping operation affects two different positions anyway. The upper limit is reduced to the max number of meaningful swaps (19) on the fly.
Optimization finishes after the list of permutations is exhausted.
n_shuffle <- rep(c(32, 10, 5, 2, 1), c(20, 40, 40, 50, 50))
scoring_f <- osat_score_generator(c("batch"), c("Treatment", "Time"))
bc1 <- optimize_design(
bc,
scoring = scoring_f,
n_shuffle = n_shuffle # will implicitly generate a shuffling function according to the provided schedule
)
#> Re-defined number of swaps to 19 in swapping function.
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Checking variances of 1-dim. score vector.
#> ... (29.908) - OK
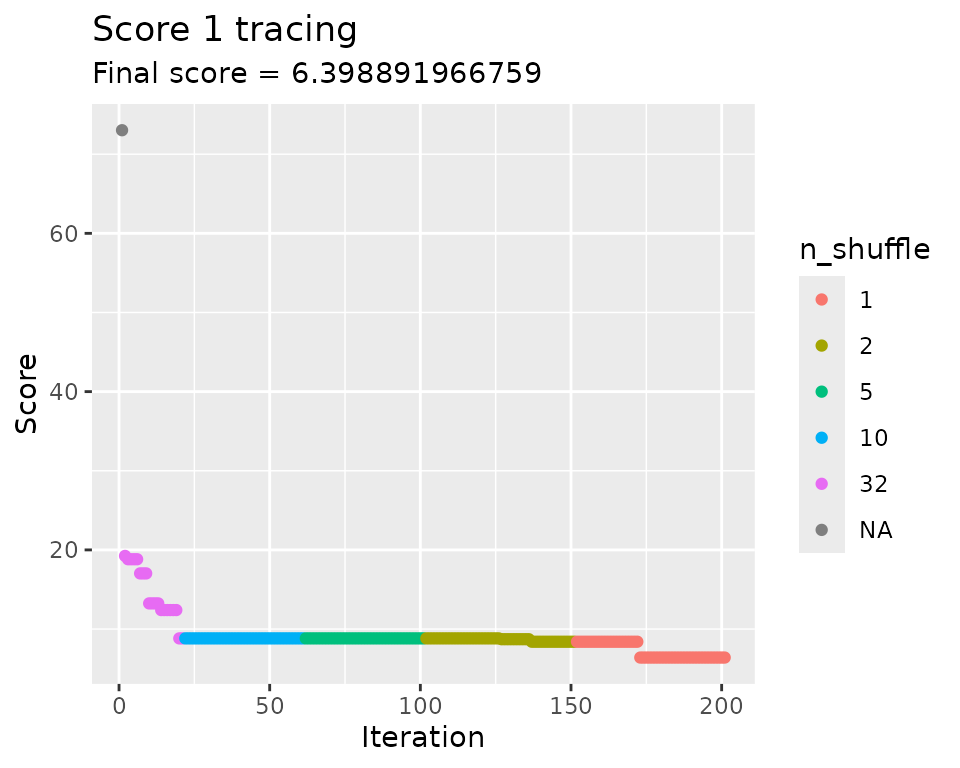
#> Initial score: 73.03
#> Achieved score: 19.241 at iteration 1
#> Achieved score: 18.82 at iteration 2
#> Achieved score: 17.03 at iteration 6
#> Achieved score: 13.241 at iteration 9
#> Achieved score: 12.399 at iteration 13
#> Achieved score: 8.82 at iteration 19
#> Achieved score: 8.715 at iteration 126
#> Achieved score: 8.399 at iteration 136
#> Achieved score: 6.399 at iteration 172
bc1$trace$elapsed
#> Time difference of 2.066754 secsOptimization trace
Custom plot with some colours:
bc1$scores_table() |>
dplyr::mutate(
n_shuffle = c(NA, n_shuffle)
) |>
ggplot2::ggplot(
ggplot2::aes(step, value, color = factor(n_shuffle))
) +
ggplot2::geom_point() +
ggplot2::labs(
title = "Score 1 tracing",
subtitle = stringr::str_glue("Final score = {bc1$score(scoring_f)}"),
x = "Iteration",
y = "Score",
color = "n_shuffle"
)
Using the internal method…
bc1$plot_trace()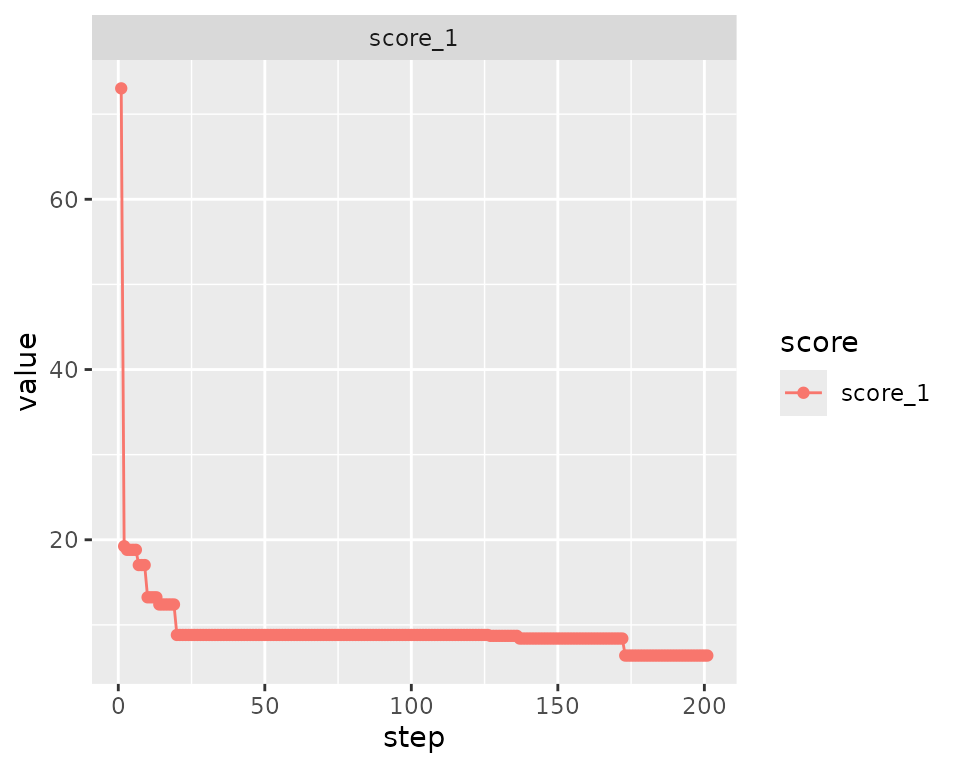
We may safely apply the batch container methods get_samples() and score() also after using the new optimization code.
Final batch layout
bc1$score(scoring_f)
#> score_1
#> 6.398892
bc1$get_samples(assignment = TRUE) |>
dplyr::filter(!is.na(Treatment)) |>
dplyr::mutate(anno = stringr::str_c(Time, " hr")) |>
ggplot2::ggplot(ggplot2::aes(x = batch, y = interaction(position, run), fill = Treatment)) +
ggplot2::geom_tile(color = "white") +
ggplot2::geom_hline(yintercept = 5.5, size = 1) +
ggplot2::geom_text(ggplot2::aes(label = anno)) +
ggplot2::labs(x = "Batch", y = "Position . Run")
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.
Perform new iterations on optimized batch container
Further optimization (using a different shuffling protocol maybe) can be done immediately on the same batch container.
n_shuffle <- rep(c(5, 2, 1), c(30, 30, 30))
bc1 <- optimize_design(
bc1,
scoring = scoring_f,
n_shuffle = n_shuffle
)
#> Checking variances of 1-dim. score vector.
#> ... (32.844) - OK
#> Initial score: 6.399
#> Achieved score: 4.504 at iteration 73Optimization with specified stopping criteria
Starting optimization from scratch, we are passing now some stopping criteria that may terminate optimization before a shuffling protocol has been exhausted.
For demonstration, we use a shuffling function now that will do 3 sample (position) swaps per iteration and can be called an arbitrary number of times. Thus, iteration has to be stopped by either the max_iter criterion or by reaching a specific minimum delta threshold (score improvement from one selected solution to the next).
bc2 <- optimize_design(
bc,
scoring = scoring_f,
n_shuffle = 3, # will implicitly generate a shuffling function that will do 3 swaps at each iteration
max_iter = 2000,
min_delta = 0.1
)
#> Checking variances of 1-dim. score vector.
#> ... (28.981) - OK
#> Initial score: 73.03
#> Achieved score: 59.452 at iteration 1
#> Achieved score: 53.452 at iteration 2
#> Achieved score: 37.452 at iteration 3
#> Achieved score: 25.452 at iteration 4
#> Achieved score: 21.452 at iteration 7
#> Achieved score: 19.452 at iteration 8
#> Achieved score: 19.346 at iteration 13
#> Achieved score: 15.346 at iteration 14
#> Achieved score: 13.767 at iteration 16
#> Achieved score: 13.662 at iteration 23
#> Achieved score: 13.557 at iteration 34
#> Achieved score: 11.978 at iteration 46
#> Achieved score: 10.399 at iteration 47
#> Achieved score: 10.083 at iteration 71
#> Achieved score: 8.504 at iteration 94
#> Achieved score: 6.715 at iteration 124
#> Achieved score: 6.609 at iteration 127
#> Achieved score: 6.504 at iteration 200
#> Achieved score: 6.083 at iteration 306
#> Achieved score: 4.504 at iteration 402
#> Achieved score: 2.925 at iteration 459
#> Achieved score: 2.609 at iteration 729
#> Achieved score: 2.294 at iteration 1955Optimization with multi-variate scoring function
Instead of passing a single scoring function, a list of multiple scoring functions can be passed to the optimizer, each of which to return a scalar value on evaluation.
By default, a strict improvement rule is applied for classifying a potential solution as “better”: each of the individual scores has to be smaller than or equal to its previous value, and one of the scores has to be changed.
However, the user could specify other methods for aggregating the scores or defining the acceptance criterion. See later examples.
The second scoring function used here is by the way rather redundant and just serves for illustration.
multi_scoring_f <- list(
osat_score_generator(c("batch"), c("Treatment", "Time")),
osat_score_generator(c("batch"), c("Treatment"))
)
bc3 <- optimize_design(
bc,
scoring = multi_scoring_f,
n_shuffle = 3,
max_iter = 200,
min_delta = 0.1
)
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Checking variances of 2-dim. score vector.
#> ... (27.872, 52.29) - OK
#> Initial score: c(73.03, 44.803)
#> Achieved score: c(57.452, 29.645) at iteration 1
#> Achieved score: c(43.452, 29.54) at iteration 2
#> Achieved score: c(29.452, 17.54) at iteration 4
#> Achieved score: c(21.452, 13.54) at iteration 6
#> Achieved score: c(17.452, 7.54) at iteration 8
#> Achieved score: c(16.294, 7.224) at iteration 12
#> Achieved score: c(8.294, 7.224) at iteration 52
#> Achieved score: c(8.188, 7.119) at iteration 86
#> Achieved score: c(8.083, 7.014) at iteration 164Note that the first score tends to yield higher values than the second one. This could be a problem when trying to select a solution based on an aggregated, overall score. We repeat the same optimization now by using the autoscaling functionality of the optimizer.
Auto-scaling scores
We’re just adding the autoscale_scores option here to
estimate the distribution of individual scores on a number of completely
random sample assignments (200 in this case) and then apply a
transformation to rescale each score to a standard normal.
Note that by ‘normalizing’ the distribution of the scores we obtain values centered around zero, thus that the optimized scores are likely to be negative. We may also want to decrease the delta_min parameter to match the new numerical range.
bc3_as <- optimize_design(
bc,
scoring = multi_scoring_f,
n_shuffle = 3,
max_iter = 200,
min_delta = 0.01,
autoscale_scores = T,
autoscaling_permutations = 200
)
#> Checking variances of 2-dim. score vector.
#> ... (27.312, 53.647) - OK
#> Creating autoscaling function for 2-dim. score vector. (200 random permutations)
#> ... Performing boxcox lambda estimation.
#> Initial score: c(5.937, 2.763)
#> Achieved score: c(3.364, 1.643) at iteration 1
#> Achieved score: c(2.669, 1.643) at iteration 3
#> Achieved score: c(1.318, 0.511) at iteration 4
#> Achieved score: c(1.009, -0.012) at iteration 6
#> Achieved score: c(0.032, -1.131) at iteration 7
#> Achieved score: c(-0.293, -1.792) at iteration 8
#> Achieved score: c(-1.645, -2.816) at iteration 16
#> Achieved score: c(-2.189, -2.816) at iteration 114Having directly comparable scores, it may be reasonable now to use a function that somehow aggregates the scores to decide on the best iteration (instead of looking at the scores individually).
An easy way to do this is to use the built-in worst_score function. This will simply set the aggregated score to whichever of the individual scores is larger (i.e. ‘worse’ in terms of the optimization).
bc4 <- optimize_design(
bc,
scoring = multi_scoring_f,
n_shuffle = 3,
aggregate_scores_func = worst_score,
max_iter = 200,
autoscale_scores = TRUE,
autoscaling_permutations = 200
)
#> Checking variances of 2-dim. score vector.
#> ... (27.052, 71.47) - OK
#> Creating autoscaling function for 2-dim. score vector. (200 random permutations)
#> ... Performing boxcox lambda estimation.
#> Initial score: c(5.158, 2.297)
#> Aggregated: 5.158
#> Achieved score: c(3.478, 1.846) at iteration 1
#> Aggregated: 3.478
#> Achieved score: c(1.596, 0.385) at iteration 2
#> Aggregated: 1.596
#> Achieved score: c(1.082, 0.826) at iteration 3
#> Aggregated: 1.082
#> Achieved score: c(0.475, 0.612) at iteration 4
#> Aggregated: 0.612
#> Achieved score: c(-0.143, 0.002) at iteration 5
#> Aggregated: 0.002
#> Achieved score: c(-0.854, -0.792) at iteration 7
#> Aggregated: -0.792
#> Achieved score: c(-2.326, -1.942) at iteration 10
#> Aggregated: -1.942
#> Achieved score: c(-2.204, -2.233) at iteration 19
#> Aggregated: -2.204
#> Achieved score: c(-3.372, -2.563) at iteration 126
#> Aggregated: -2.563
#> Achieved score: c(-3.333, -3.106) at iteration 127
#> Aggregated: -3.106
#> Achieved score: c(-3.333, -4.037) at iteration 179
#> Aggregated: -3.333
#> Achieved score: c(-4.117, -4.037) at iteration 195
#> Aggregated: -4.037Another - more interesting - option would be to aggregate the two scores by taking their sum. This way both scores will influence the optimization at every step.
For illustration, we omit the n_shuffle parameter here,
which will lead by default to pairwise sample swaps being done on each
iteration.
bc5 <- optimize_design(
bc,
scoring = multi_scoring_f,
aggregate_scores_func = sum_scores,
max_iter = 200,
autoscale_scores = TRUE,
autoscaling_permutations = 200
)As a final example, we calculate the (squared) L2 norm to actually aggregate the two scores. Not that this choice is not really motivated in this case, but it could be used if optimization was carried on meaningful distance vectors or normalized n-tuples.
Note that we don’t use the auto-scaling in this case as the L2-norm based optimization would force both normalized scores towards zero, not the minimal (negative) value that would be desired in that case.
bc5_2 <- optimize_design(
bc,
scoring = multi_scoring_f,
aggregate_scores_func = L2s_norm,
max_iter = 200,
)Passing a customized shuffling function
It is recommended to use the n_shuffle parameter to
steer the optimization protocol. However, you may also provide a
dedicated shuffling function that on each call has to return a shuffling
order (as integer vector) or a list with the source and destination
positions (src and dst) of the sample positions to be swapped.
The following example uses a template for creating complete random shuffles across all available positions in the batch container. Note that this is usually not a good strategy for converging to a solution.
bc6 <- optimize_design(
bc,
scoring = scoring_f,
shuffle_proposal_func = complete_random_shuffling,
max_iter = 200
)
#> Checking variances of 1-dim. score vector.
#> ... (28.187) - OK
#> Initial score: 73.03
#> Achieved score: 20.715 at iteration 1
#> Achieved score: 18.82 at iteration 2
#> Achieved score: 15.346 at iteration 6
#> Achieved score: 13.241 at iteration 14
#> Achieved score: 12.82 at iteration 47
#> Achieved score: 10.82 at iteration 73
#> Achieved score: 8.82 at iteration 99Using simulated annealing (SA) for optimization
Esp. for very large search spaces, better solutions can be quite successfully obtained by a SA protocol which allows the optimizer to jump over ‘energy barriers’ to more likely converge at lower local minima.
The optimizer usually remembers the permutation with the best overall score to start with, but this behavior can be changed by supplying a simulated annealing protocol, most simply by generating a ready-made function template.
It is generally recommended for SA to make small changes at each step, like allowing just 1 sample swap per iteration.
Currently the simulated annealing protocol requires a single double value score to be optimized. Choose an appropriate aggregation function if you happen to have multiple scores initially.
bc7 <- optimize_design(
bc,
scoring = scoring_f,
n_shuffle = 1,
acceptance_func = mk_simanneal_acceptance_func(),
max_iter = 200
)
#> Checking variances of 1-dim. score vector.
#> ... (30.919) - OK
#> Initial score: 73.03
#> Achieved score: 65.03 at iteration 1
#> Achieved score: 65.03 at iteration 2
#> Achieved score: 59.452 at iteration 3
#> Achieved score: 59.452 at iteration 4
#> Achieved score: 59.452 at iteration 5
#> Achieved score: 59.452 at iteration 6
#> Achieved score: 59.452 at iteration 7
#> Achieved score: 55.452 at iteration 8
#> Achieved score: 55.452 at iteration 9
#> Achieved score: 51.452 at iteration 10
#> Achieved score: 51.873 at iteration 11
#> Achieved score: 52.188 at iteration 12
#> Achieved score: 52.188 at iteration 13
#> Achieved score: 46.188 at iteration 15
#> Achieved score: 42.188 at iteration 16
#> Achieved score: 40.083 at iteration 17
#> Achieved score: 40.083 at iteration 18
#> Achieved score: 38.188 at iteration 19
#> Achieved score: 34.188 at iteration 20
#> Achieved score: 30.504 at iteration 21
#> Achieved score: 30.504 at iteration 22
#> Achieved score: 30.504 at iteration 23
#> Achieved score: 30.504 at iteration 24
#> Achieved score: 30.504 at iteration 25
#> Achieved score: 28.504 at iteration 26
#> Achieved score: 22.504 at iteration 27
#> Achieved score: 18.504 at iteration 28
#> Achieved score: 18.504 at iteration 29
#> Achieved score: 18.504 at iteration 30
#> Achieved score: 18.504 at iteration 31
#> Achieved score: 18.504 at iteration 33
#> Achieved score: 16.504 at iteration 35
#> Achieved score: 16.399 at iteration 36
#> Achieved score: 16.399 at iteration 38
#> Achieved score: 16.399 at iteration 39
#> Achieved score: 16.399 at iteration 40
#> Achieved score: 16.399 at iteration 41
#> Achieved score: 16.399 at iteration 42
#> Achieved score: 14.399 at iteration 44
#> Achieved score: 14.399 at iteration 45
#> Achieved score: 12.82 at iteration 48
#> Achieved score: 12.82 at iteration 49
#> Achieved score: 12.82 at iteration 56
#> Achieved score: 10.925 at iteration 60
#> Achieved score: 10.925 at iteration 61
#> Achieved score: 8.925 at iteration 64
#> Achieved score: 8.925 at iteration 89
#> Achieved score: 8.504 at iteration 93
#> Achieved score: 8.504 at iteration 95
#> Achieved score: 8.504 at iteration 96
#> Achieved score: 8.504 at iteration 99
#> Achieved score: 8.504 at iteration 112
#> Achieved score: 8.188 at iteration 119
#> Achieved score: 8.083 at iteration 144
#> Achieved score: 8.083 at iteration 145
#> Achieved score: 7.978 at iteration 174The trace may show a non strictly monotonic behavior now, reflecting the SA protocol at work.
bc7$plot_trace()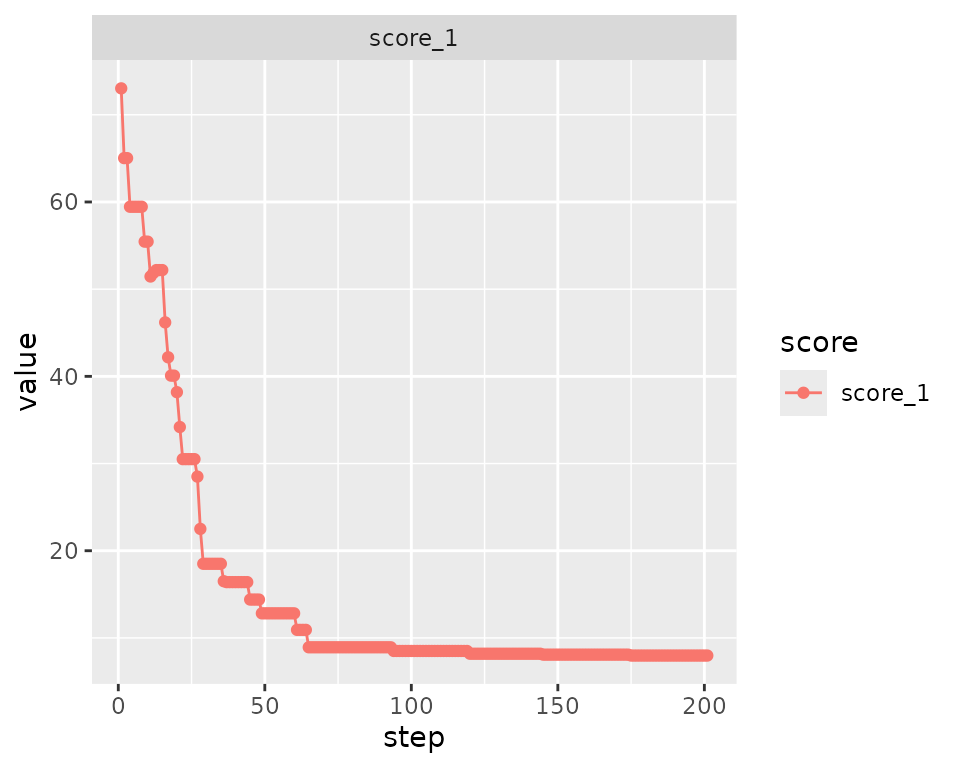
Better results and quicker convergence may be achieved by playing with the starting temperature (T0) and cooling speed (alpha) in a specific case.
bc8 <- optimize_design(
bc,
scoring = scoring_f,
n_shuffle = 1,
acceptance_func = mk_simanneal_acceptance_func(mk_simanneal_temp_func(T0 = 100, alpha = 2)),
max_iter = 150
)
#> Checking variances of 1-dim. score vector.
#> ... (41.437) - OK
#> Initial score: 73.03
#> Achieved score: 66.925 at iteration 1
#> Achieved score: 56.925 at iteration 2
#> Achieved score: 54.925 at iteration 3
#> Achieved score: 46.925 at iteration 4
#> Achieved score: 48.925 at iteration 5
#> Achieved score: 40.925 at iteration 6
#> Achieved score: 32.925 at iteration 7
#> Achieved score: 30.925 at iteration 9
#> Achieved score: 30.925 at iteration 10
#> Achieved score: 30.925 at iteration 11
#> Achieved score: 26.925 at iteration 13
#> Achieved score: 18.925 at iteration 18
#> Achieved score: 16.925 at iteration 19
#> Achieved score: 16.925 at iteration 20
#> Achieved score: 16.925 at iteration 22
#> Achieved score: 16.925 at iteration 23
#> Achieved score: 16.925 at iteration 24
#> Achieved score: 14.925 at iteration 26
#> Achieved score: 14.925 at iteration 43
#> Achieved score: 13.03 at iteration 57
#> Achieved score: 11.346 at iteration 61
#> Achieved score: 9.346 at iteration 79
#> Achieved score: 7.662 at iteration 96
bc8$plot_trace()
Full blown example
The following example puts together all possible options to illustrate the flexibility of the optimization.
n_shuffle <- rep(c(3, 2, 1), c(20, 20, 200))
bc9 <- optimize_design(
bc,
scoring = list(
osat_score_generator(c("batch"), c("Treatment", "Time")),
osat_score_generator(c("batch"), c("Treatment")),
osat_score_generator(c("batch"), c("Time"))
),
n_shuffle = n_shuffle,
aggregate_scores_func = sum_scores,
acceptance_func = mk_simanneal_acceptance_func(mk_simanneal_temp_func(T0 = 500, alpha = 1)),
max_iter = 200,
min_delta = 1e-8,
autoscale_scores = T
)
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Warning in osat_score(bc, batch_vars = batch_vars, feature_vars = feature_vars,
#> : NAs in features / batch columns; they will be excluded from scoring
#> Checking variances of 3-dim. score vector.
#> ... (32.721, 70.614, 105.045) - OK
#> Creating autoscaling function for 3-dim. score vector. (100 random permutations)
#> ... Performing boxcox lambda estimation.
#> Initial score: c(9.253, 3.275, 5.019)
#> Aggregated: 17.547
#> Achieved score: c(6.898, 2.618, 3.304) at iteration 1
#> Aggregated: 12.819
#> Achieved score: c(6.609, 2.427, 2.847) at iteration 2
#> Aggregated: 11.883
#> Achieved score: c(4.878, 2.258, 2.43) at iteration 3
#> Aggregated: 9.566
#> Achieved score: c(3.415, 2.7, 2.004) at iteration 4
#> Aggregated: 8.119
#> Achieved score: c(1.23, 1.387, 0.578) at iteration 5
#> Aggregated: 3.195
#> Achieved score: c(-0.369, -0.875, 0.578) at iteration 6
#> Aggregated: -0.666
#> Achieved score: c(0.818, -0.277, 0.376) at iteration 7
#> Aggregated: 0.917
#> Achieved score: c(0.018, 0.019, -0.698) at iteration 8
#> Aggregated: -0.661
#> Achieved score: c(-1.665, 0.004, -0.31) at iteration 9
#> Aggregated: -1.971
#> Achieved score: c(-0.697, 0.125, -0.325) at iteration 11
#> Aggregated: -0.897
#> Achieved score: c(-0.304, 0.93, -0.717) at iteration 13
#> Aggregated: -0.091
#> Achieved score: c(-0.326, -0.503, 0.568) at iteration 14
#> Aggregated: -0.262
#> Achieved score: c(0.103, -0.487, -0.106) at iteration 15
#> Aggregated: -0.489
#> Achieved score: c(0.167, -0.754, -0.12) at iteration 16
#> Aggregated: -0.707
#> Achieved score: c(0.568, -0.422, -0.404) at iteration 18
#> Aggregated: -0.258
#> Achieved score: c(-1.074, -0.422, -0.736) at iteration 19
#> Aggregated: -2.231
#> Achieved score: c(-1.504, -0.422, -1.664) at iteration 22
#> Aggregated: -3.59
#> Achieved score: c(-1.944, -0.422, -1.664) at iteration 25
#> Aggregated: -4.03
#> Achieved score: c(-1.944, -0.422, -1.664) at iteration 27
#> Aggregated: -4.03
#> Reached min delta in 27 iterations.
bc9$plot_trace()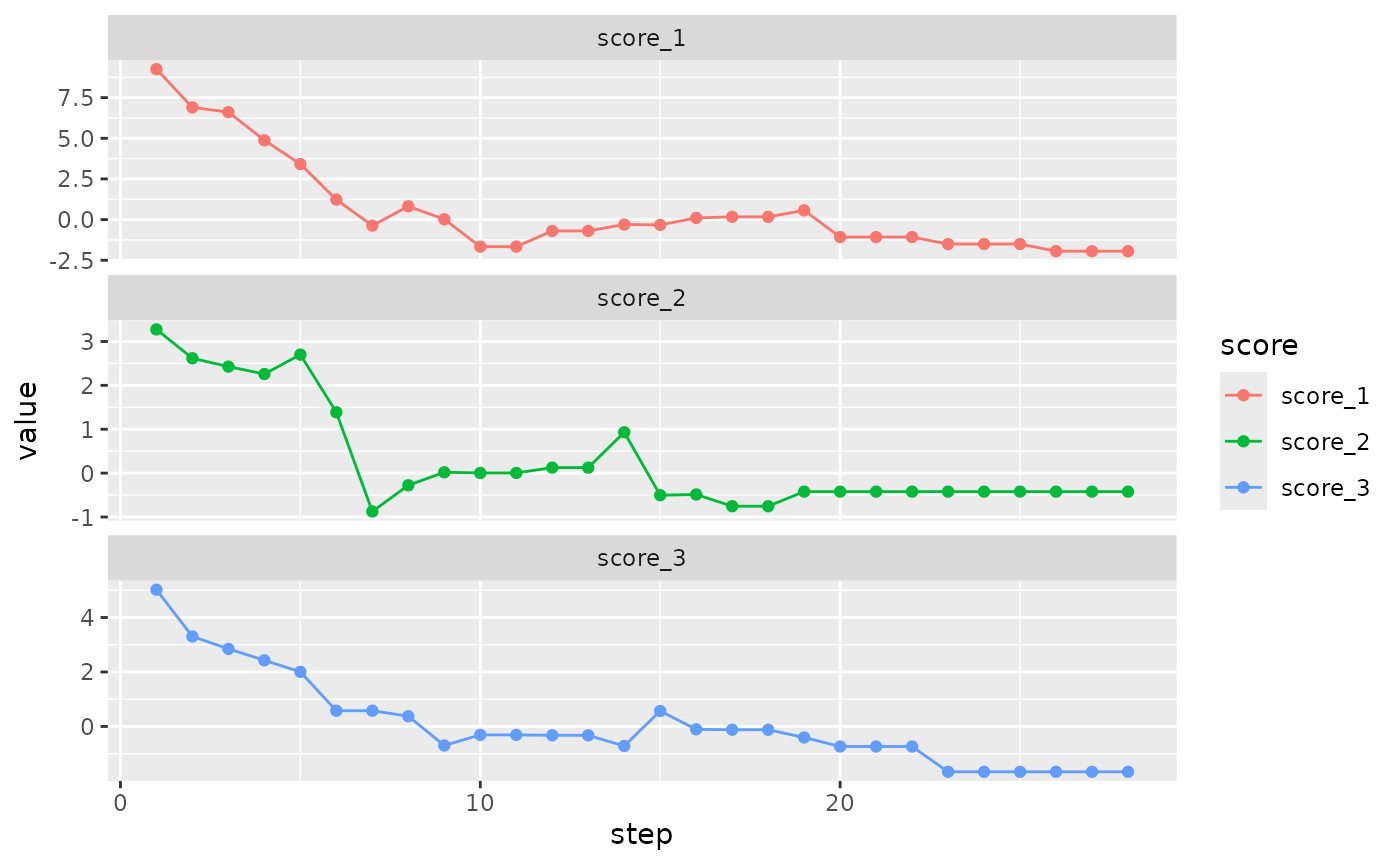
bc9$get_samples(assignment = TRUE) |>
dplyr::mutate(batch = factor(batch)) |>
ggplot2::ggplot(ggplot2::aes(x = batch, fill = Treatment, alpha = factor(Time))) +
ggplot2::geom_bar()
#> Warning: Using alpha for a discrete variable is not advised.